Introduction
Li Fei-Fei’s recent article, “From Language to the World: Spatial Intelligence is the Next Frontier for AI,” has sparked significant discussion in Silicon Valley, with many calling it a “declaration of spatial intelligence.” Following this, her co-founded World Labs launched the world’s first large-scale world model product, Marble. Shortly after, she appeared on Lenny’s Podcast to discuss her recent initiatives, her thoughts on the future of AI, the technological path of world models, and why spatial intelligence will be crucial for AI in the next decade.

AI’s Evolution
In the hour-long conversation, Li Fei-Fei reflected on the historical shifts in AI from its winter to resurgence, candidly discussing the anxieties and pressures of entrepreneurship. She pointed out that AGI (Artificial General Intelligence) is “more of a marketing term than a scientific one,” emphasizing that the biggest shortcoming of current AI is its lack of spatial intelligence—the ability to navigate three-dimensional spaces, manipulate objects, and predict physical phenomena. She explained why relying solely on data and computing power has led to a “bitter lesson” that cannot mature robots, and why no one should be marginalized in the AI era.
From ImageNet to World Models
Today, AI is a hot topic, but few remember that just nine years ago, calling oneself an “AI company” was almost commercial suicide. Li Fei-Fei recalled, “From mid-2015 to mid-2016, some tech companies even avoided using the term AI because they weren’t sure if it was a pejorative.” At that time, AI was deep in its winter, with limited public interest and research funding.
The thawing of this winter can be traced back to a breakthrough in 2012. That year, Geoffrey Hinton’s team achieved groundbreaking success in the ImageNet competition using neural network algorithms, widely considered the birth of modern AI or deep learning. The foundation of this revolution was the ImageNet dataset, which Li Fei-Fei began building in 2006.

In 2000, Li Fei-Fei began her PhD at Caltech, where AI researchers had already realized that purely rule-based programming could not endow machines with true cognitive abilities. The concept of machine learning was emerging, allowing computers to learn patterns from data rather than writing rules for every situation.
However, Li Fei-Fei quickly identified a commonly overlooked bottleneck: “We had various mathematical models, including neural networks and Bayesian networks, but these models lacked training data.” This insight stemmed from observing how humans learn. Human learning relies on vast accumulations of experience, and evolution itself is a long-term big data learning process. At that time, AI models were like malnourished children, struggling to perform despite sophisticated algorithms.
This observation led her and her students to embark on what seemed like a “completely crazy” project: meticulously collecting 15 million images from the internet to create a classification system containing 22,000 concepts.
This bold gamble ultimately paid off. The two graphics cards used by Hinton’s team and the 15 million labeled images became the prototype for the golden recipe of modern AI.
This “golden recipe” continues to this day. “If you look at the technology behind ChatGPT, it still uses these three key elements: internet-scale data (mainly text), a much more complex but still neural network architecture than in 2012, and a large number of GPUs,” Li Fei-Fei pointed out.
However, as large language models swept the globe, Li Fei-Fei turned her attention to another direction. In 2019, when GPT-2 was released, she, as co-director of Stanford’s Human-Centered AI Institute (HAI), engaged in deep discussions with colleagues in natural language processing. “We all saw the future,” she recalled. But she also realized that language alone is not enough.
Spatial Intelligence: An Overlooked Cognitive Infrastructure
In Li Fei-Fei’s view, the fundamental limitation of today’s AI lies in its lack of spatial intelligence. “While large language models are eloquent, they lack experience; they are knowledgeable but fail to ground themselves,” she wrote, “They are wordsmiths in the dark.”
Li Fei-Fei provided a simple example: “You show the most advanced multimodal large language models (MLLMs) videos of several office rooms and ask them to count how many different chairs there are. This is something a school-age child can do, but AI cannot.” Not to mention tasks that require mentally rotating objects, estimating distances, or predicting basic physical phenomena, where AI often performs no better than random guessing.
In contrast, spatial intelligence permeates every aspect of human activity. From everyday tasks like parking, catching a ball, or pouring coffee, to the ancient Greek scholar Eratosthenes measuring the Earth’s circumference using shadows, and Watson and Crick discovering the double helix structure of DNA using physical models, these moments of human brilliance all rely on an understanding and manipulation of space.
“Our view of the world is holistic,” Li Fei-Fei emphasized, “not just what we are looking at, but how everything relates spatially, what it means, and why it matters. Understanding this through imagination, reasoning, creation, and interaction—rather than merely describing it—is the power of spatial intelligence.”
In the interview, she further elaborated on why spatial intelligence is so critical for AI: “Imagine a chaotic first response scene, perhaps a fire, traffic accident, or natural disaster. If you immerse yourself in those scenarios, thinking about how people organize themselves to save lives, prevent further disasters, and extinguish flames—much of this is about movement, immediate understanding of objects and the world, and situational awareness. Language is part of it, but in many cases, language cannot help you extinguish flames.”
“The core of human cognition is not just language,” Li Fei-Fei emphasized, “but the ability to understand and operate in three-dimensional space. From parking to grabbing keys, from designing buildings to discovering the double helix structure of DNA, all rely on spatial intelligence.”
Current AI models perform surprisingly poorly in this regard. The most advanced multimodal large language models (MLLMs) often perform no better than random guessing in estimating distances, directions, and sizes. They cannot mentally rotate objects, navigate mazes, or predict basic physical phenomena. While AI-generated videos may be novel, they often lose coherence after just a few seconds.
This is precisely why Li Fei-Fei began systematically thinking about world models in 2022. This concept is a natural extension of her years of research in computer vision and robotics. In 2024, she first systematically articulated the vision of spatial intelligence and world models in a TED talk, and a few months later, she co-founded World Labs with Justin Johnson, Christoph Lassner, and Ben Mildenhall.

Li Fei-Fei defined three core capabilities for world models: generativity—capable of creating worlds with geometric and physical consistency; multimodality—able to process various inputs such as images, videos, text, and actions; and interactivity—able to predict the next state of the world based on actions. In simple terms, while large language models teach machines to read and write, world models will teach them to observe and build.
The Birth of Marble: From Research to Product
About one to two months ago, the World Labs team first saw their model generate navigable three-dimensional worlds through simple text and image prompts. The shock of that moment was perhaps similar to witnessing the first truly effective deep neural network trained on ImageNet. After more than a year of hard development, the world’s first generative three-dimensional world model was finally born.
This is Marble, released in November. It is fundamentally different from existing video generation tools. “The world is not passively watching videos go by,” Li Fei-Fei explained using Plato’s allegory of the cave, “The essence of vision is understanding the three-dimensional or four-dimensional world from two dimensions.” Video generation models output flat two-dimensional worlds, while Marble outputs a three-dimensional world with depth and spatial structure—users can freely explore, interact, and even export specific viewpoints as video clips.
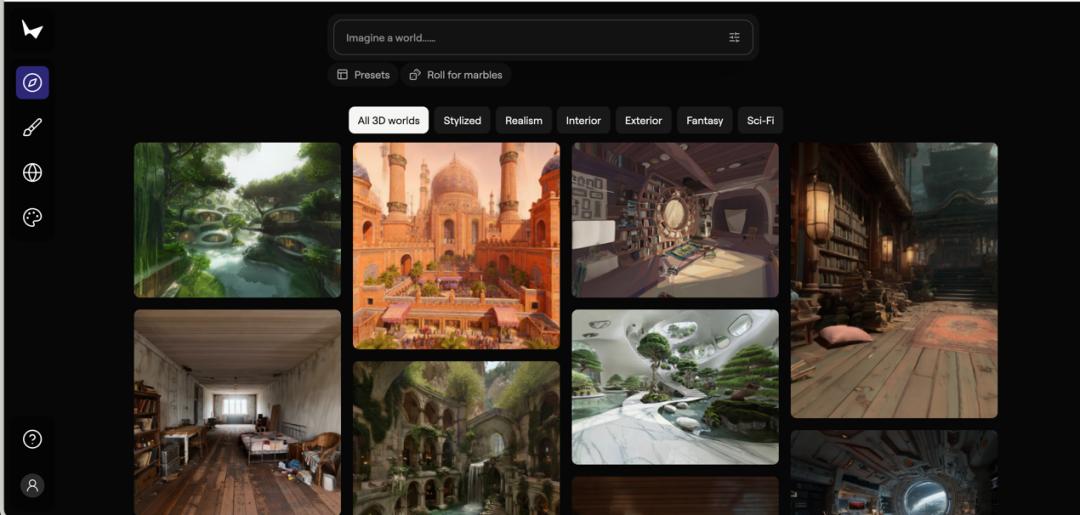
After the product launch, the diversity of application scenarios exceeded the team’s expectations. Film production companies used it to significantly accelerate virtual production processes, stating it reduced production time by 40 times, as creators could freely position cameras and shoot segments within the three-dimensional scenes generated by Marble. Game developers exported Marble scenes as mesh data for VR or traditional game development.
Even more surprising applications came from the scientific research field. A psychology team contacted World Labs, hoping to create experimental environments for psychiatric research using Marble. “They needed to understand how patients’ brains respond to immersive environments with different characteristics, such as cluttered or tidy spaces. For researchers, obtaining such immersive scenes is very challenging, requiring too much time and budget to create. Marble can almost instantly provide a large number of experimental environments,” Li Fei-Fei said.
Robot researchers also saw the value of Marble. Training robots requires learning in diverse synthetic environments, but creating this training data has always been a significant pain point. “You want robots to perform actions in three-dimensional worlds, but training data lacks actions in those three-dimensional worlds,” Li Fei-Fei pointed out. “World models can generate those synthetic environments. Otherwise, humans would have to manually construct every asset for robots, which would take much longer.”
There were even inquiries about whether Marble could be used for exposure therapy. “Last night, a friend called me, talking about his fear of heights, asking if Marble could be used for treatment,” Li Fei-Fei said.
The Future of Robotics: Why the Bitter Lesson Alone is Not Enough
During the interview, the host, representing investor Ben Horowitz, posed a question: Why can’t the famous “bitter lesson” in AI history alone solve the robot problem?
The “bitter lesson” originates from a paper by Turing Award winner Richard Sutton, whose core argument is that simple models with massive data always outperform complex models with limited data. This principle has been perfectly validated in language models, and Li Fei-Fei’s motivation for building ImageNet was also rooted in the belief in the power of big data.

However, the robotics field is different. “Language model researchers are fortunate,” Li Fei-Fei admitted, “They have a perfect setup: the training data is text (ultimately tokens), and the model output is also text. The objective function and training data align perfectly.”
In contrast, robotics faces more complex challenges. First, data acquisition is difficult. While web videos can be used, “you want actions in the three-dimensional world from robots, and training data lacks these.” Researchers have to find different methods to fill this “square peg in a round hole” problem, such as remote operation data or synthetic data.
Secondly, current mainstream methods segment data into one-dimensional or two-dimensional token sequences, making some originally simple spatial tasks extremely difficult. “World models will play a decisive role in providing this information,” Li Fei-Fei said, “but we must be cautious because we are still in the early stages, and the bitter lesson remains to be validated.”
More critically, robots are physical systems, not just algorithms. Li Fei-Fei reminded, “To make robots work, we need not only brains but also physical bodies and application scenarios.” She cited self-driving cars as an example: from the 2005 Stanford Racing Team completing 130 miles in the Nevada desert to today’s Waymo operating on the streets of San Francisco, it has taken 20 years. “And self-driving cars are just metal boxes operating on two-dimensional surfaces, aiming not to hit anything. Robots, on the other hand, are three-dimensional objects operating in three-dimensional worlds, whose goal is precisely to make contact with things.”
In doing this work, Li Fei-Fei’s respect for the human brain has grown. “Our brains consume only about 20 watts of power, dimmer than any light bulb in the room, yet can do so much. Honestly, the longer I work in AI, the more I respect humanity.”
The Myth of AGI and the Future of AI
“World models” have long been considered one of the key technologies leading to AGI, yet as a supporter and promoter of world models, Li Fei-Fei’s stance on when AGI will arrive is somewhat surprising; she believes that “AGI is more of a marketing term than a scientific term.”
As a scientist, she takes the AI itself seriously, which is the grand question that has existed since Turing posed the question “Can machines think?” in the 1940s. “I entered this field inspired by this bold question: Can machines think and act like humans? For me, that has always been the North Star of AI. From this perspective, I don’t know what the difference between AI and AGI is.”
She pointed out that no one has truly defined AGI. “There are many different definitions, from some kind of superpower of machines to whether machines can become economically viable agents in society—in other words, able to make a living. Is that a definition of AGI?”
When asked whether the current technological path can achieve AGI, Li Fei-Fei’s response is both realistic and ambitious: “I absolutely believe we need more innovation. More data, more GPUs, and larger current model architectures still have much work to do, but I also absolutely believe we need to innovate more.”
She listed tasks that AI still cannot accomplish: counting how many chairs are in a video, demonstrating creativity similar to Newton’s derivation of laws of motion from observing celestial movements, or exhibiting emotional intelligence in conversations between teachers and students. “No profound scientific discipline in human civilization has ever said, ‘We are done; we no longer need to innovate.’ AI, as one of the youngest disciplines in human civilization, is still exploring the surface.”
Recently, DeepMind’s CEO Demis Hassabis proposed an interesting AGI testing method: if the most advanced model is provided with all the information up to the end of the 20th century, can it derive Einstein’s groundbreaking discoveries? “We are far from that,” Li Fei-Fei said, “In fact, the situation is worse. Even if we give AI all the data, including modern astronomical instrument data that did not exist in Newton’s time, to create the equations of motion from the 17th century, today’s AI cannot do that.”
Li Fei-Fei added that emotional intelligence is also a significant gap. A student walks into a teacher’s office to discuss dynamics, enthusiasm, and distress; the depth of that conversation is something even today’s most powerful chatbots cannot reach.
“AI is one of the youngest disciplines in human civilization, and we are still exploring the surface,” she said. No mature scientific field would claim, “We are done; we no longer need to innovate.” Despite the incredible progress made by large language models, Li Fei-Fei firmly believes we need more innovation, not just larger datasets, more GPUs, and larger existing architectures.
Human-Centered: The Ultimate Destination of Technology
As the interview drew to a close, Li Fei-Fei shared a belief that has run through her entire career: “Your field is called artificial intelligence, but it is not ‘artificial’ at all. It is inspired by humans, created by humans, and most importantly, it impacts humans.” This is something she often reminds her graduates, and it was also the reason she decided to leave the industry in 2018 and return to Stanford to establish HAI.
That year, she published an article in The New York Times calling for a human-centered guiding framework for the development and application of AI. HAI subsequently became the largest AI research institution globally, involving hundreds of faculty members from seven Stanford schools, spanning medicine, education, sustainable development, and the humanities.

However, Li Fei-Fei emphasized that she is not a utopian. “AI will affect work and people; this is an unavoidable fact. But I believe that what AI can and will do now and in the future depends on us, on people.” She believes that technology has a net positive impact on human civilization because innovation is the essence of humanity. From written records thousands of years ago to today, humans have continuously innovated and improved tools to make life better, work more efficient, and build civilization.
Yet, she is also acutely aware of the double-edged nature of technology: “If we, as a society and as individuals, do not do the right things, we can also mess things up.” She urges everyone to care about AI because it will affect your personal life, your community, society as a whole, and future generations. “Caring about this as responsible individuals is the first and most important step.”
At the end of the interview, Li Fei-Fei answered a question she is often asked while traveling around the world: If I am a musician, middle school teacher, nurse, accountant, or farmer, do I still have a role in the AI era?
Her answer is, “This is the most important question in AI. The answer is a resounding ‘yes.’ Everyone has a role in AI.” She gave the example that if you are a young artist, you should embrace AI as a tool—embrace Marble to help you tell your story in the most unique way. If you are a nurse, she wants you to know that a significant part of her career has been devoted to medical AI research because healthcare workers are overburdened, and AI can and should greatly assist them.
“Silicon Valley often struggles to communicate heart-to-heart with ordinary people,” she said, “We always throw around terms like ‘unlimited productivity’ or ‘unlimited leisure time.’ But ultimately, AI is about people. No technology should take away human dignity. Human dignity and agency should be at the core of every technology’s development, deployment, and governance.”
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.