Claude AI’s skill mechanism hides consumption traps! Tests show that with 15 unused skills, a single sentence consumes 51K tokens, while reducing to 5 drops to 31K—those seemingly ‘idle and free’ abilities are quietly consuming tokens in every conversation. This article deeply dissects Anthropic’s underlying mechanism, revealing the dual consumption logic of full preloading and polling judgments for skill descriptions, along with optimization solutions and three practical strategies to help you cut hidden AI costs.

I said the same sentence, and the token consumption differed by 20K.
The only variable was the number of skills. Once I had 15, and another time only 5.
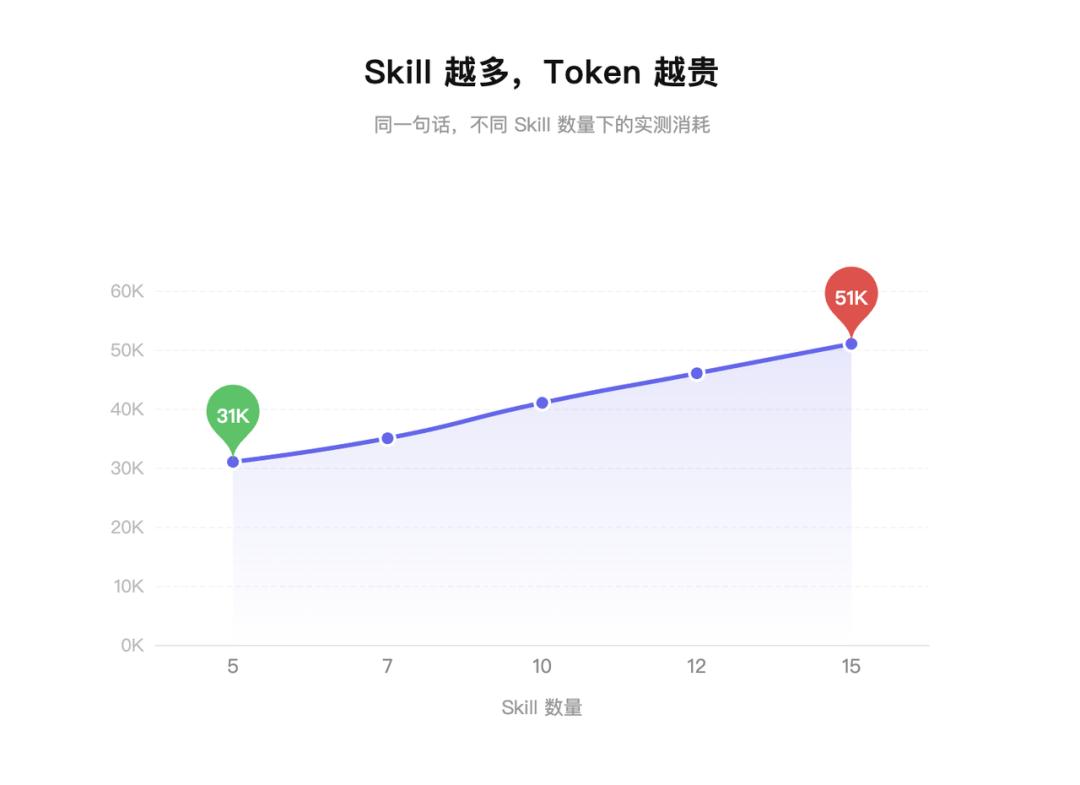
At first, I didn’t believe it. The 10 skills I deleted had nothing to do with the sentence I said, which was just a regular work instruction. But the bill doesn’t care about that. When I had 15 skills, one sentence cost 51K tokens. After reducing to 5, the same sentence only cost 31K.
The difference of 20K was entirely due to those skills I thought were free.
At that moment, I realized my understanding of skills had been wrong from the start.
What did I think before? Probably something like this: skills are a reserve of abilities, the more the better, easily accessible when needed, and idle when not in use, at zero cost. Sounds reasonable, right? It’s like having apps on your phone—if they’re not opened, they don’t consume battery.
But Claude is not a phone. Skills are not apps.
You Think They’re Free, But They Charge Every Round
First, we need to clarify how Claude reads your message.
When you send a message, Claude does not receive just that message; it receives an entire context package. What’s inside? System prompts, previous conversation history, tool definitions, and all the names and descriptions of installed skills.
Note, it includes all installed skills, not just the few you want to use this time.
The logic here is that Claude needs to know what cards it has before deciding which card to play. Therefore, before each round of conversation, all skill metadata is injected into the context. This happens not just occasionally, but with every round, every sentence.
So, having 15 skills is more expensive than having 5. It’s not because it does more work; it’s purely because the additional 10 skill descriptions are added to the context every time.
Let me give you a somewhat imprecise analogy to help you understand.
Imagine you run a company, and before every meeting, your assistant reads all employee resumes to decide who to invite. With 5 employees, it reads 5 resumes. With 50 employees, it reads 50 resumes. This meeting requires 2 people to be present, but the remaining 48 resumes are still read. The time spent reading resumes is your token consumption.
Anthropic’s own engineering data has confirmed the severity of this issue. Without any optimization, the token cost for tool definitions can soar from 55K to 134K. This number is not an edge case; it’s a normal result under typical configurations.
Let’s do a more straightforward calculation. The description text for a skill conservatively estimates between 200 to 500 tokens. Ten skills mean a fixed cost of 2000 to 5000 tokens deducted every round, regardless of whether you use them. The input token price for Sonnet is about 3 dollars per million tokens. If you talk to Claude 100 times a day, within a month, those skills that have never been used could quietly consume dozens of dollars.
What’s worse is that this consumption accumulates. In multi-round conversations, each round includes all previous history and re-injects the skill descriptions. By the 30th round, the context you send out could be several times larger than in the 1st round. A significant portion of this increased volume is contributed by those skills that will never be called upon.
Many people find their Claude bills inexplicably high, repeatedly searching for reasons, suspecting it’s due to complex tasks or lengthy conversations. Few think to check how many skills they have installed.
But that’s often the most expensive line item.
Claude Checks the Roster Before Speaking
Understanding the injection process is just the beginning.
There’s another layer that makes this even more expensive: Claude doesn’t just passively inject skill descriptions into the context; it also actively scans through them, determining whether to call a skill for the current task.
This judgment process consumes tokens as well.
For example, if you ask Claude to help you write an email, before it starts writing, it must review all installed skill descriptions, asking one by one: Do I need to use the data analysis skill for writing this email? Do I need to use the code review skill? It goes through each one, even if the answer is all ’no’.
This is the mechanism behind my comparative experiment.
When I had 15 skills, Claude scanned 15 descriptions and made 15 judgments. With only 5 skills, it only made 5 judgments. The 20K token difference comes partly from the volume of skill descriptions and partly from the cost of this individual judgment process.
I’m confident about this because Anthropic later developed a tool called ToolSearch, which does this: instead of scanning all tool definitions every round, it tells Claude, “You have a search capability; find the tools you need.” This changes the tool definitions from full preloading to on-demand retrieval.
The existence of this tool itself is proof.
If having more skills didn’t affect token consumption, Anthropic wouldn’t need to create ToolSearch. It’s precisely because the default mechanism ties skill quantity to token consumption that a tool is needed to break this binding relationship.
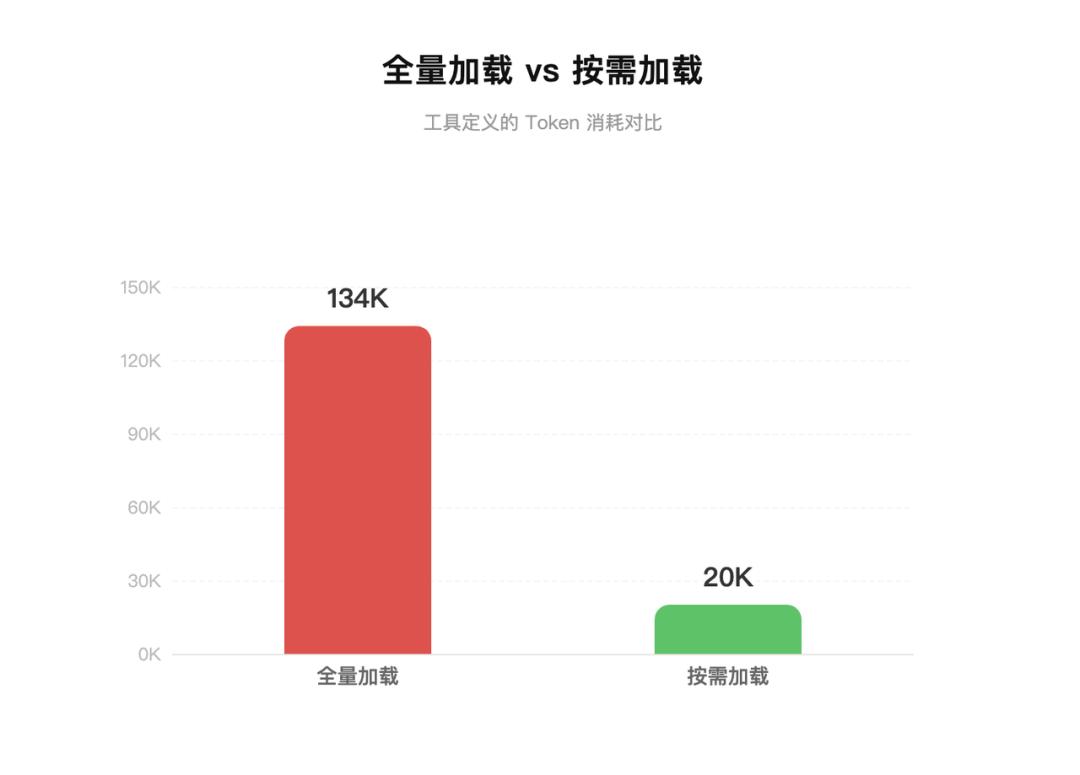
Official data states that after enabling ToolSearch for on-demand loading, context consumption related to tools can be reduced by 85%. What does this number mean? It means that without optimization, nearly half of your context is occupied by tool and skill descriptions.
Returning to the earlier meeting analogy, ToolSearch effectively changes the process from reading all employee resumes to only having a thin roster available before the meeting, and checking records as needed. The roster is thin, and checking records incurs a fee.
This makes it possible for having 2000 skills to be cheaper than having 5, but only if you use on-demand loading; otherwise, the number of skills directly determines token consumption.
However, the problem is that most people don’t know this mechanism and haven’t actively enabled it. They still use the default full loading, where every skill counts every round.
Another issue makes it harder to detect. The consumption of skills is hidden. You can see how many tokens were used in each conversation, but it’s hard to intuitively link that number to the unused skills. Unless you do a comparative experiment like I did, keeping everything else constant while only changing the number of skills and saying the same sentence to check the bill.
The results are quite uncomfortable.
Some have conducted more systematic tests. Reducing a system prompt from 2500 lines to core instructions decreased tokens by 30-40% with almost no change in Claude’s performance. Skills follow the same principle. We think having more installed equals stronger capability, but the extra portion contributes little to the outcome while significantly impacting token costs.
The illusion of capability and the reality of the bill exist simultaneously. Most people only notice the former.
The Solution is Not to Install Less, But Not to Let Them Hang There Forever
At this point, you might be thinking: then just don’t install too many skills, right? Keep it lean.
This idea isn’t wrong, but it’s only half the truth.
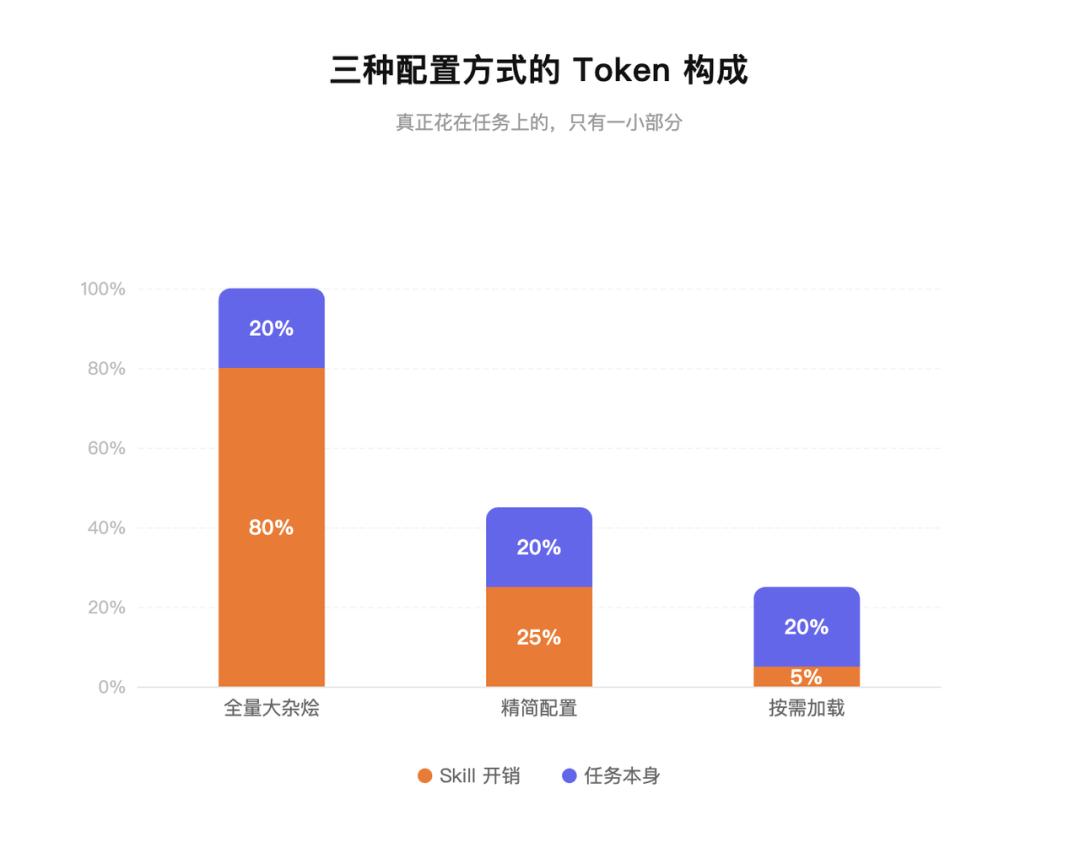
The root cause isn’t how many skills you have installed, but when those skills are loaded. You can have 20 skills but use on-demand loading, and the cost might be lower than 5 skills with full loading. Conversely, you could have only 5 skills, but if 4 of them are never used, you’re still paying for those 4 every round.
Quantity is not the core variable. The loading mechanism is.
Before you get a chance to tinker with the underlying loading mechanism, there are three immediate actions you can take that will yield results.
First, conduct a skill audit.
List all the skills you have installed in Claude and ask yourself: which ones have I actively used in the past month? Most people will find that they frequently use only 3 to 5, while the rest are skills they thought would be useful but haven’t touched since installation. This portion is what you’re paying for every round without ever receiving any value.
Second, split configurations by scenario; don’t pursue a ‘jack-of-all-trades’ approach.
Having a configuration with 20 skills sounds appealing, but from a token efficiency perspective, it’s the most expensive way to configure. A smarter approach is to have one set of configurations for coding, another for content creation, and a third for daily work communication. Each set should only include the skills that will genuinely be used in that scenario, switching as needed.
This may be slightly more cumbersome operationally, but the effects are tangible. Each scenario’s token consumption will be significantly lower than a generic configuration crammed with everything.
Third, familiarize yourself with ToolSearch and deferred loading.
ClaudeCode now supports deferred loading. When the number of tools exceeds a certain threshold, the system will automatically delay most tool definitions until they are called, while providing Claude with a search tool to look up functions as needed.
This mechanism doesn’t require you to write code, but you need to be aware of its existence and check if your configurations have triggered this mode. There are explanations in Anthropic’s official documentation, and spending 20 minutes reading it is worthwhile.
Ultimately, this issue reflects a more universal problem: the anxiety of capability in the AI tool era.
New skills are released, and people install them. When they see others recommending a tool, they install it. They think they might need it in the future, so they install it. This logic existed in the smartphone app era and has been amplified in the AIAgent era because the installation cost of skills is so low—just a click, and it’s done in seconds.
The low installation cost creates an illusion: installing incurs no loss.
But the loss is always there, just in a form you can’t see, hidden in the token bills of every conversation.
More and more people are beginning to realize that the cost of using AI tools is not just the subscription fee; it also includes those hidden costs created by your own configurations. Often, these hidden costs are more expensive than the subscription fee itself.
When I conducted that comparative experiment, I didn’t expect the difference to be so significant.
51K and 31K. I stared at these two numbers for a while, and my thoughts weren’t about how much I saved, but rather another question: what was I really after when I installed those skills?
A sense of security, perhaps. The feeling that having them meant I was prepared. What if I needed them one day?
But needing them one day comes with a cost. Money is deducted quietly every day, every round, every sentence in those tokens. I thought I was buying capability; in reality, I was purchasing relief from anxiety.
This mindset doesn’t just apply to skills. Subscribing to a bunch of memberships just in case, saving a bunch of articles just in case, signing up for a bunch of courses just in case. Most things end up sitting in a corner, quietly incurring costs.
Your Claude is not a toolbox. A toolbox filled with tools has no cost when you open the lid. Claude is different; every time it opens the lid, it must read through all the tool descriptions before deciding which one to use.
Cleaning up those unused skills is not about losing capability.
It’s about reclaiming the rent you’ve been paying without ever receiving any value.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.